How to Protect Intellectual Property of Text Generation APIs
Problem Overview
Nowadays, many technology corporations have invested a plethora of workforce and computation to data collection and model training, in order to deploy well-trained commercial models as pay-as-you-use services (in the form of APIs) on their cloud platforms. Unfortunately, recent works have validated that the functionality of these APIs can be stolen through extraction/imitation attacks, since the enormous commercial benefit allures competing companies or individual users to extract or steal these successful APIs.
Such attacks cause severe intellectual property (IP) violations of the target API and stifle the creativity and motivation of our research community. Beyond imitation attacks, the attacker could potentially surpass victims by conducting unsupervised domain adaptation and multi-victim ensemble[1].
Proposed Methodology
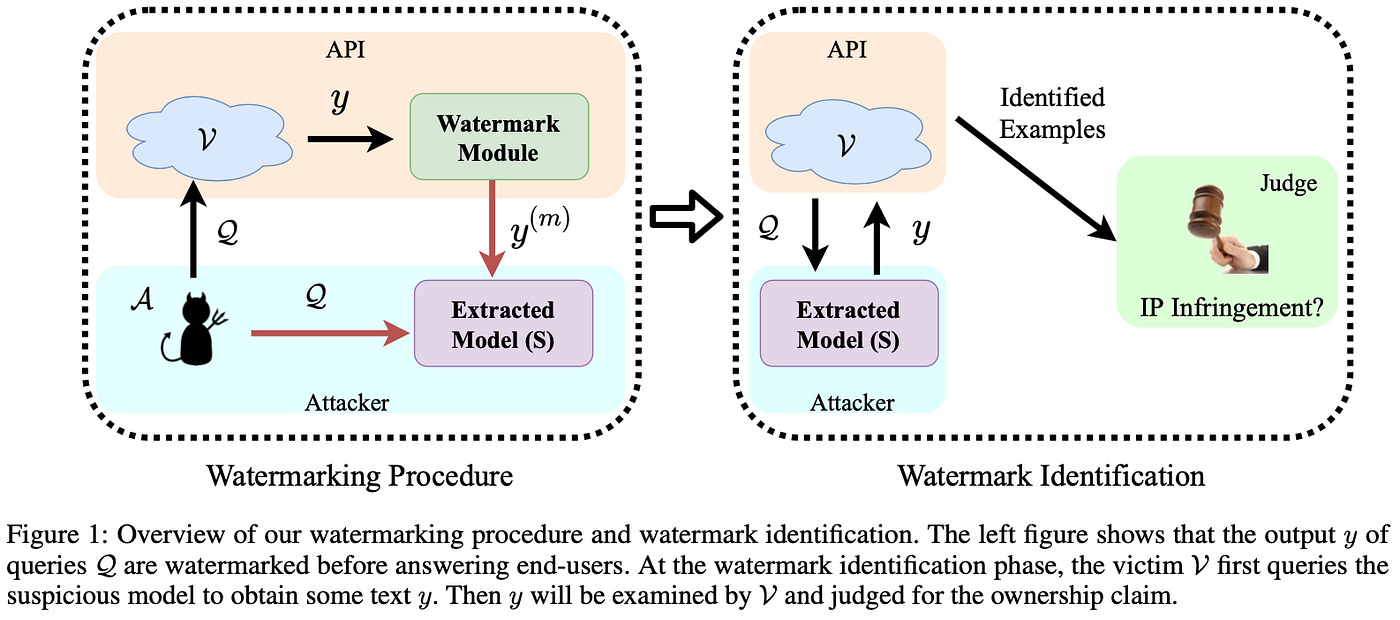
In order to protect victim models, He et al. [2] first introduced a watermarking algorithm to text generation and utilized the null-hypothesis test as a post-hoc identification of an IP infringement on the extracted/imitation model, as shown in Figure 1.
However, the word distribution is distorted, which could be utilized by attackers to infer the watermarked words via sufficient statistics of the frequency change of candidate watermarking words. As an example shown in Figure 2, the replaced words and their substitutions are those with most frequency decrease ratios and increase ratios, respectively.

Figure 2: Ratio change of word frequency of top 100 words between benign and watermarked corpora used by [2], namely Pb(w)/Pw(w).
To address this drawback, we further developed a more stealthy watermarking method called CATER to protect the IP of text generation APIs [3]. The stealthiness of the new watermarks is achieved by incorporating high-order linguistic features as conditions that trigger corresponding watermarking rules.

Figure 3: The workflow of CATER IP protection for Generation APIs. CATER first watermarks some of the responses from victim APIs. Then, CATER identifies suspicious attacker’s API by watermark verification.
Figure 3 provides an overview of CATER. CATER injects the watermarks in conditional word distribution, while maintaining the original word distribution. Given a condition c ∈ C and a group of semantically equivalent words W, one can replace any words w ∈ W with each other. The objective of conditional watermarking rules is formulated as:

The first part is indistinguishable objective, which is mainly to ensure that the overall word frequency of the target word (that is, the watermark word) will not change greatly before and after the watermark. The second part is distinct objective, which aims to ensure that, under specified conditions, the word frequency of the target word is inconsistent before and after the watermark, so as to achieve the purpose of detection after the watermark.
To construct the watermarking conditions C, two fundamental linguistic features are considered, i) part-of-speech and ii) dependency tree, and their high-order variations as conditions.
Performance
Text Generation Tasks. Two widespread text generation tasks are examined: machine translation (WMT14 German (De) →English (En) translation) and document summarization (CNN/DM), which have been successfully deployed as commercial APIs.
Metrics. To judge whether the suspected model is obtained through model stealing, null-hypothesis is used as the basis for detection. If the frequency of watermarked words is higher, the p-value is lower, and the suspect model is more likely to be obtained through model stealing. To test the impact of watermarking on utility, we measure the text generation quality of the imitation model, the higher the quality, the smaller the negative impact of watermarking.
Basic Settings. We start with the most straightforward case, in which we assume the victim model V and the imitation model S use the same training data, but S uses the response y′ with CATER instead of the ground-truth y.
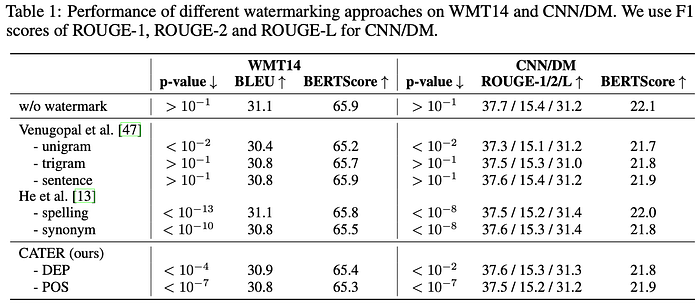
Table 1 presents the watermark identifiability and generation quality of studied text generation tasks. Both [2] and CATER obtain a sizeable gap in the p-value, and demonstrate a negligible degradation in BLEU, ROUGE, and BERTScore, compared to the non-watermarking baseline. Although CATER is slightly inferior to [2] in p-value, watermarks in [2] can be easily erased, as their replacement techniques are not invisible.
IP Identification under Architectural Mismatch. The architectures of remote APIs are usually unknown to the adversary. To demonstrate that our approach is model-agnostic, we use BART-family models as victim models and vary architectures of imitation models from (m)BART, Transformer-base, and ConvS2S.
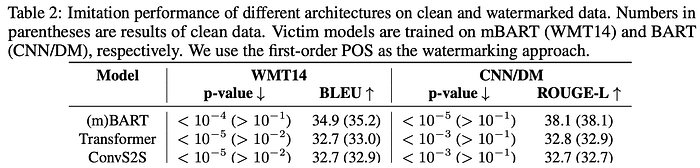
As shown in Table 2, the effect of CATER is not limited to the model, even if the model structure of the victim model and the imitation model are inconsistent, CATER can effectively protect the copyright.
IP Identification on Cross-domain Imitation. In fact, there could be a domain mismatch between the training data of the victim model and queries from the adversary. In order to exhibit that our approach is exempt from the domain shift, we use two out-of-domain datasets (IWSLT14(tedtalk)& OPUS(Law)) to conduct the imitation attack for the machine translation task.

As shown in Table 3, even if the attacker uses data from different domains for model stealing, CATER can still effectively protect the copyright of the victim model.
Analysis on Adaptive Attacks. Given the case that a savvy attacker might be aware of the existence of watermarks, they might launch countermeasures to remove the effects of the watermark. We examine two types of adaptive attacks that try to erase the effects of the watermark: i) vanilla watermark removal, and ii) watermarking algorithm leakage.
Vanilla Watermark Removal. Under this setting, the attacker can adopt an existing watermark removal technique. We employ ONION [4], a popular defensive avenue for data poisoning in NLP, which adopts GPT-2 to expel outlier words. The defense results are shown in Table 4, in which we find that ONION cannot erase the injected watermarks. Meanwhile, it drastically diminishes the generation quality of the imitation model.

Watermarking Algorithm Leakage. Under this case, we assume attackers have access to the full details of our watermarking algorithm, i.e., the same watermarking dictionary and the features for constructing watermarking conditions. This is the most substantial attacker knowledge assumption we can imagine, aside from the infeasible case that they know the complete pairs of watermarks we used. After collecting responses from the victim model, the attackers can leverage the leaked knowledge to analyze the responses to find the used watermarks, i.e., the number of sparse entries. In our paper, we have theoretically proved that such reverse engineering is infeasible [3].
In Figure 4, we further show that even with such a strong attacker knowledge, the amount of potential candidate watermarks (orange curve) is still astronomical times larger than the used number of watermarks (blue curve). Thus, malicious users would have difficulty removing watermarks from the responses; unless they lean toward modifying all potential watermarks. Such a brute-force approach can drastically debilitate the performance of the imitation attack, causing a feeble imitation.
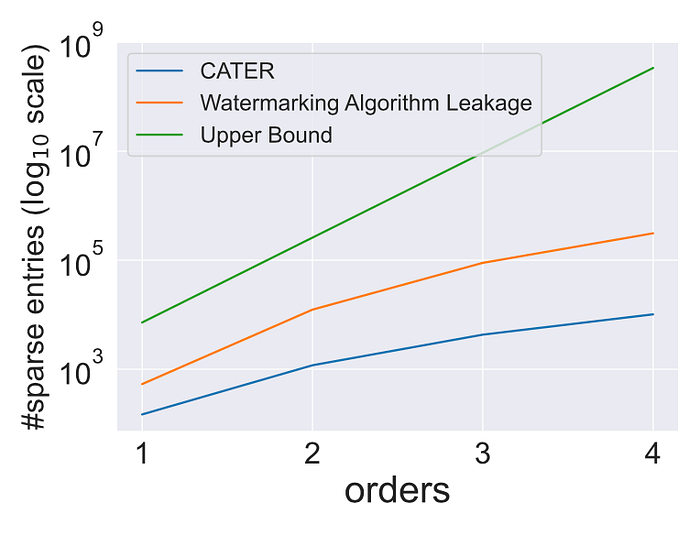
Figure 4: The number of sparse entries (suspected watermarks) of top 200 words with watermarking algorithm leakage under different orders (orange) on the training data. CATER indicates the actual number of watermarks used by our watermarking system (blue). POS feature is used where |F| = 36. The upper bound indicates all possible combinational watermarks (green).
Conclusion
In view of the significant harm of model theft to commercial APIs, we propose how to effectively protect the copyright of the victim model through a condition-based watermarking algorithm (CATER) [3]. We have fully verified the protection effect of CATER through a large number of test scenarios. CATER can be used to remind developers of commercial APIs to take effective protection measures, so as to avoid the loss of legal rights and interests caused by model theft.
In addition to protecting the IP of APIs, CATER also has the potential to be used to solve the copyright disputes in AI-generated content (AIGC).
All images are from the author’s [AAAI’22 Oral] and [NeurIPS’22] papers as listed in the reference.
Where to find the paper and code?
Paper: https://openreview.net/pdf?id=L7P3IvsoUXY
Code: https://github.com/xlhex/cater_neurips
Authors: Xuanli He (UCL), Qiongkai Xu (The University of Melbourne), Yi Zeng (Sony AI intern), Lingjuan Lyu (Sony AI), Fangzhao Wu (MSRA), Jiwei Li (Shannon.AI, Zhejiang University), Ruoxi Jia (Virginia Tech)
Reference
1. [COLING’22 Long] Student Surpasses Teacher: Imitation Attack for Black-Box NLP APIs. Qiongkai Xu, Xuanli He, Lingjuan Lyu, Lizhen Qu, Gholamreza Haffari.
2. [AAAI’22 Oral] Protecting Intellectual Property of Language Generation APIs with Lexical Watermark. Xuanli He, Qiongkai Xu, Lingjuan Lyu*, Fangzhao Wu, Chenguang Wang.
3. [NeurIPS’22] CATER: Intellectual Property Protection on Text Generation APIs via Conditional Watermarks. Xuanli He, Qiongkai Xu, Yi Zeng, Lingjuan Lyu*, Fangzhao Wu, Jiwei Li, Ruoxi Jia.
4. [EMNLP’21] Onion: A simple and effective defense against textual backdoor attacks. Fanchao Qi, Yangyi Chen, Mukai Li, Yuan Yao, Zhiyuan Liu, and Maosong Sun.
