Extract and Transfer, Your BERT is Vulnerable!
- Problem overview
Natural language processing (NLP) tasks have been revolutionised by the pre-trained language models, such as BERT. This allows corporations to easily build powerful APIs by encapsulating fine-tuned BERT models for downstream tasks. However, when a fine-tuned BERT model is deployed as a service, it may suffer from different attacks launched by the malicious users. In this work, we first present how an adversary can steal a BERT-based API service (the victim/target model) on multiple benchmark datasets with limited prior knowledge and queries. We further show that the extracted model can lead to highly transferable adversarial attacks against the victim model. Our studies indicate that the potential vulnerabilities of BERT-based API services still hold, even when there is an architectural mismatch between the victim model and the attack model.
2. Our proposed framework

2.1 Model Extraction Attack (MEA): In the first phase, we assume that a “victim model” is commercially available as a prediction API for target task. An adversary attempts to reconstruct a local copy (“extracted model”) via querying the victim model. Our goal is to extract a model with comparable accuracy to the victim model. Generally, MEA can be formulated as a two-step approach, as illustrated by the left figure in Figure 1.
- Attackers craft a set of inputs as queries, then send them to the victim model (BERT-basedAPI) to obtain predictions;
- Attackers reconstruct a local copy of the victim model as an “extracted model” using the retrieved query-prediction pairs.
Once the local copy is obtained, the attacker no longer needs to pay the original service provider. The attacker can even deploy the stolen model as a new service provider at a lower price, thus eroding the market shares of the competing companies.
2.2 Adversarial Example Transfer (AET): In the second phase, we leverage the transferability of adversarial examples: we first generate adversarial examples for the extracted model, then transfer the generated adversarial examples to the victim model. The intuition is that adversarial examples generated by the extracted model are transferable to the victim model. Here we use the extracted model to serve as a surrogate to craft adversarial examples in a white-box manner. Such attack aggravates the vulnerabilities of victim models.
3 Performance evaluation
3.1 NLP tasks and datasets

3.2 AET results under different query distribution and size
To examine the correlation between the query distribution (D_A) and the effectiveness of our attacks on the victim model trained on data from D_V, we explore the following two different scenarios:
(1) we use the same data as the original data of the victim model (D_A=D_V). Note that attackers have no true labels of the original data; (2) we sample queries from different distribution but same domain as the original data (D_A ≠ D_V).
We vary the number of queries from size {0.1, 0.5,1,5}x of the training data size of the victim model to simulate query budgets. According to Table 2, we have observed that: 1) the success of the extraction correlates to the domain closeness between the victim’s training data and the attacker’s queries; 2) using same data even outperforms the victim models, which is also known as self-distillation; 3) albeit the different distributions brought by review and news corpora, our MEA can still achieve 0.85–0.99× victim models’ accuracies when the number of queries varies in {1x,5x}. Although more queries suggest a better extraction performance, small query budgets (0.1x and 0.5x) are often sufficiently successful.

Costs Estimation: We analyse the efficiency of MEA on various classification datasets. Each query is charged due to a pay-as-you-use policy adopted by service providers. We estimate costs for each task in Table 3 according to Google APIs and IBM APIs . Considering the efficacy of model extraction, the cost is highly economical and worthwhile.

3.3 AET results
To generate natural adversarial examples, we follow the protocol (Sun et al., 2020a) that leverages the gradients of the gold labels w.r.t the embeddings of the input tokens to find the most informative tokens, which have the largest gradients among all positions within a sentence. Then we corrupt the selected tokens with one of the following typos: 1) Insertion; 2) Deletion; 3) Swap; 4) Mistype: Mistyping a word though keyboard, such as “oh” ->“0h”; 5) Pronounce: Wrongly typing due to the close pronounce of the word, such as “egg” -> “agg”; 6) Replace-W: Replace the word by the frequent human behavioural keyboard typo based on the Wikipedia statistics.
In order to understand whether our extracted model manages to improve the transferability, we also launch a list of black-box adversarial attacks in the same manner. Table 4 demonstrates that our pseudo white-box attack makes the victim model more vulnerable to adversarial examples in terms of transferability — more than twice effective in the best case, compared to the black-box counterparts.
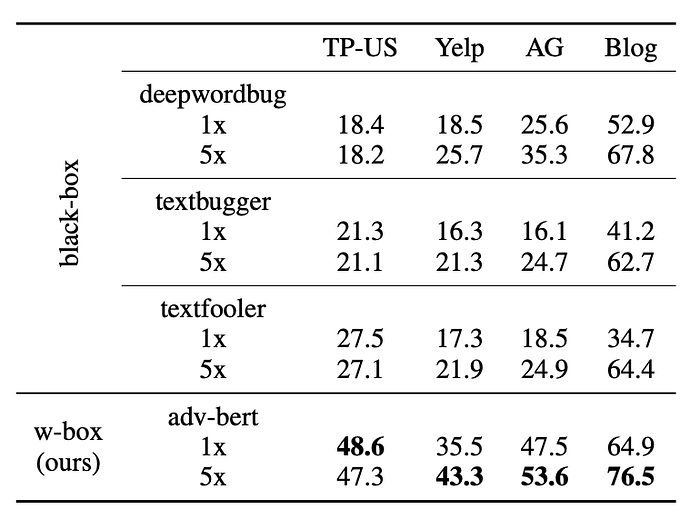
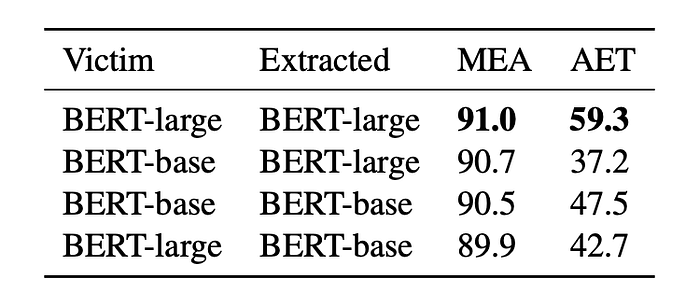
3.4 Architectural mismatch
In practice, the adversary may not know the victim’s model architecture. Hence we also study the attacking behaviours under different architectural settings. According to Table 5, when both the victim and the extracted models adopt BERT-large, the vulnerability of the victim is magnified in all attacks, which implies that the model with higher capability is more vulnerable to our attacks. As expected, the efficacy of AET can be alleviated when an architectural mismatch exists.
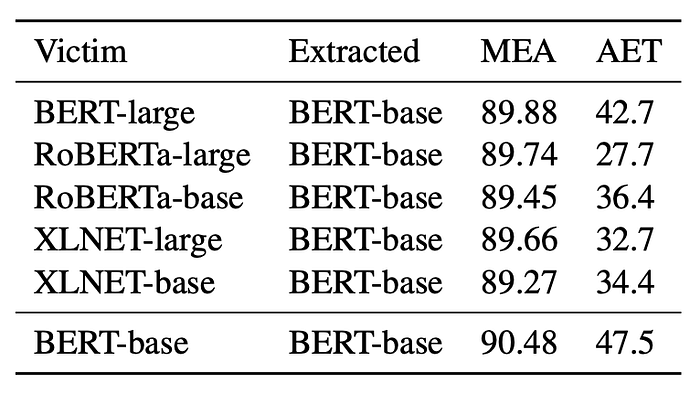
In Table 6, we experiment with more mismatched models, including BERT, RoBERTa and XLNET. Although the architectural difference can cause some drops in MEA and AET, overall the proposed attacks are still effective.
4. Defence
We next briefly discuss two defence strategies the victim model can adopt to counter these attacks.
• Softening predictions (SOFT). A temperature coefficient τ on softmax layer manipulates the posterior probability distribution. A higher τ leads to smoother probability, whereas a lower one produces a sharper distribution. When τ=0, the posterior probability becomes a hard label.
• Prediction perturbation (PERT). Another defence method is adding normal noise with variance σ to the predicted probability distribution. The larger the variance of the noise distribution, the stronger the defence.
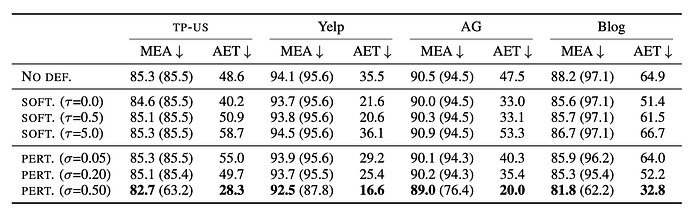
Table 7 indicates that varying temperature on softmax cannot defend the victim model against MEA, except for τ=0 (hard label), which can degrade all attacks to some extent. Regarding perturbation, it can achieve a significant defence at the cost of the accuracy of the victim models.
5. Conclusion
This work goes beyond model extraction from BERT-based APIs, and we also identify the extracted model can largely enhance adversarial example transferability even in difficult scenarios, i.e., limited query budget, queries from different distributions, or architectural mismatch. Extensive experiments based on representative NLP datasets and tasks under various settings demonstrate the effectiveness of our attacks against BERT-based APIs.
6. Where to find the paper and code?
Paper: https://arxiv.org/abs/2103.10013
Code: https://github.com/ xlhex/extract_and_transfer
Reference:
@inproceedings{he2021model,
title={Model Extraction and Adversarial Transferability, Your BERT is Vulnerable!},
author={He, Xuanli and Lyu, Lingjuan and Xu, Qiongkai and Sun, Lichao},
booktitle = {Proceedings of NAACL-HLT 2021},
year={2021}
}
